
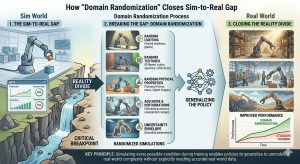



For years, artificial intelligence researchers have wrestled with a frustrating paradox. An AI model that performs flawlessly in a high‑fidelity simulation can often collapse when deployed on real hardware—a phenomenon known as the sim‑to‑real or Sim2Real gap. Wind gusts, surface friction variations, sensor noise, and unexpected lighting all create unpredictable physical environments that break the assumptions baked into our models. Traditionally, bridging this gap meant either perfecting simulators to mirror reality (an impossible task) or collecting massive amounts of expensive real‑world data for training.
But a new paradigm is emerging: domain randomization. By deliberately injecting controlled randomness into simulation parameters during training, we’re teaching AI systems that the real world is just another “variation” they’ve already mastered. This article explores what domain randomization is, how it works, where it’s being applied, and why it represents a genuine breakthrough in physical AI.
The Core Idea: Training for Robustness, Not Fidelity
Instead of chasing photorealistic simulation mirrors, domain randomization embraces uncertainty. At its heart, the technique treats the simulator as a tunable black box whose parameters—mass, friction, drag coefficients, sensor noise, even gravity direction—can be sampled at random during each training step or episode. The goal is simple yet profound: if a policy works across thousands of wildly different simulated worlds, it will likely work in any real one.
This flips the traditional simulation‑reality trade‑off. Rather than spending millions simulating every possible variation to match reality, we expose our models to an enormous spectrum of synthetic variations, forcing them to learn invariant representations that generalize beyond the data.
How Domain Randomization Works
The technique typically randomizes several categories:
-
Physics Parameters
- Friction coefficients (e.g., 0.5–1.5)
- Mass and inertia distributions (±5% to ±20%)
- Damping and stiffness values
- Gravity vector offsets (±0.3 g)
-
Visual & Sensor Randomization
- Lighting intensity, color temperature, position (pan/tilt/roll)
- Textures, object colors, and background clutter
- Camera field of view shifts and focal length changes
- Noise injection to vision and sensor data
-
Dynamics & Dynamics
- Action delays (0–50 ms)
- Observation noise for force/torque sensors
- Random external forces or disturbances
-
Environmental Factors
- Object positions, orientations, and counts
- Scene clutter and background composition
- Weather effects in outdoor simulations
OpenAI’s Automatic Domain Randomization (ADR) is a prime example. Starting with a non‑randomized environment, the system automatically expands randomization ranges as training performance plateaus. This “meta‑learning” loop pushes environments to ever greater difficulty until the neural network exhibits emergent robustness—exactly the behavior needed for deployment.
Real‑World Impact: From Robots to Drones
The technique isn’t just theoretical. It’s already transforming robotics, autonomous driving, and industrial inspection:
-
OpenAI’s Dactyl Hand (2019): Trained a robotic hand to solve Rubik’s Cubes using only simulated data. When faced with physical disturbances—poking the cube with a plush giraffe or applying a rubber glove—the real robot adjusted its behavior without explicit reprogramming, proving that simulation‑learned policies can handle unforeseen perturbations.
-
ANYmal Robotics (2022‑2024): Trained quadrupedal locomotion in NVIDIA Isaac Gym with domain randomization. The real-world ANYmal traversed rocky mountains, steep staircases, snow, and mud with a 98% success rate on first deployment—demonstrating how randomization turns “hard” training environments into de facto robustness trainers.
-
Industrial Vision Systems: Companies like Siemens and Bosch are using domain randomization to train defect‑detection models for metal parts. By randomizing lighting, textures, camera angles, and background clutter, they eliminate the need for costly real‑world data collection while improving inspection model generalization.
Expert Insight: The Nuanced View
While most sources agree on the value of domain randomization, there are valid caveats:
-
Missing Parameters: Victor Osei warns that if a critical real-world feature (e.g., thermal expansion) is absent from simulation or not randomized, policies can fail even when all other parameters are covered. Randomization only works if it covers the entire parameter space of what exists in reality.
-
Simulation Fidelity Limits: As noted by Luca — AI & Coffee — domain randomization builds on a foundation. If the simulator cannot model a real‑world phenomenon (e.g., flexible joints vs. rigid ones), training is doomed, regardless of how much we randomize other parameters.
-
Sample Efficiency Trade‑off: Randomizing too broadly or for too long makes learning harder. OpenAI’s Dactyl required months of GPU time; modern research combines randomization with limited real data to accelerate convergence.
The Bigger Picture: A New Era of Physical AI
Domain randomization is part of a broader shift toward Physical AI—a field that views simulation not as a perfect replica but as a tool for inducing robustness. Complementary techniques like real‑to‑sim alignment, causal world models, and latent domain alignment further enhance this ecosystem.
- Real‑to‑Sim Transfer: Converts physical robots or environments into synthetic data, allowing offline training.
- World Models & Causal Regularization: Learn not just correlations but true dynamics, ensuring policies respond appropriately to any action.
- Latent Alignment: Makes the internal representations of simulated and real data mutually intelligible.
NVIDIA’s Isaac Platform 2.0, launched in February 2026, exemplifies this future: photorealistic simulation paired with one‑click Sim‑to‑Real deployment and a foundation model that automatically tunes physics to match reality.
Conclusion
The sim‑to‑real gap was once considered an insurmountable obstacle. By embracing randomness, we’re turning it into the solution. Domain randomization teaches AI to be indifferent to superficial variations—wind gusts, friction shifts, lighting flips—because those variations are now part of its training regimen.
As robotics and autonomous systems grow more embedded in the real world, the ability to train robust policies without massive real‑world data collection becomes a decisive advantage. Domain randomization isn’t just a technical trick; it’s a philosophical shift: robustness is a design goal, not an afterthought. And with ongoing refinements—adaptive ranges, hybrid methods that blend simulation and real data, and tools like NVIDIA Cosmos—this breakthrough will only accelerate.
In the words of Luca — AI, Coffee & Structural Thinking:
“With enough variability in the simulator, the real world may appear to the model as just another variation.”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}