




Introduction: Beyond Text to Touch
The artificial intelligence industry has been transformed over the past few years. What began with large language models (LLMs) that could converse, write code, and generate text has rapidly evolved into something far more consequential: Physical AI – models that don’t just understand the world through text, but interact with it directly.
Drones, rovers, and humanoid robots are no longer just executing pre-programmed sequences. They’re being equipped with models that perceive their surroundings, reason about physical constraints, and execute fluid motor actions in one continuous loop. This shift marks a fundamental change: from AI that thinks in text to AI that thinks and acts in the physical world.
At the heart of this revolution are Vision-Language-Action (VLA) models, which integrate perception, reasoning, and control into unified architectures. But here’s what makes this possible: training these sophisticated systems requires an astronomical amount of visual and physical data—data you can’t ethically or economically gather from real-world trials alone.
This is where high-fidelity simulators enter the picture. They’ve become the invisible backbone generating the synthetic multi-modal datasets that VLA models need to learn. Among the leading platforms, solutions built on photorealistic rendering engines like Unreal Engine have emerged as critical tools for training the next generation of embodied AI.
What Are VLA (Vision-Language-Action) Models?
The Paradigm Shift: From Text to Touch
Traditional LLMs operate primarily in textual space—they predict the next token in a text sequence. They excel at language tasks but lack true understanding of physics or real-world dynamics. A traditional LLM can tell you that “if I drop this glass, it will break,” but it doesn’t inherently know how to control an end-effector to perform that action.
VLA models change this fundamental relationship. Instead of treating perception (seeing an obstacle) and control (turning the vehicle) as separate software blocks, VLA models process visual feeds and directly output motor/control actions in one fluid loop.
The Architecture: Unified Perception and Control
A VLA’s architecture shares a common high-level structure across implementations:
Stage 1: Perception and Reasoning Core A pre-trained Vision-Language Model (VLM) serves as the perception and reasoning core. It encodes camera images and natural language instructions into a shared latent space. These VLMs are trained on large multimodal datasets and can perform image understanding, visual question answering, and complex reasoning.
Stage 2: Action Decoding An action decoder maps those tokens to continuous output actions that directly control robot joints or vehicle actuators. The model learns to associate high-level concepts (like “object categories” and “spatial relations”) with low-level physical actions, eliminating the partitioning typical of traditional robotic systems.
Key Design Choices in VLA Architecture
Action Representation Two main approaches exist:
- Discrete Token Output: Used by models like RT-2 and OpenVLA, where each motion primitive is represented as a sequence of discrete tokens—much like language generation.
- Continuous Output: Pioneered by π0 (pi-zero) through diffusion/flow models, which directly output continuous actions for smooth, high-frequency control (up to 50Hz).
Single-Model vs. Dual-System Design
- Single-model design (RT-2, OpenVLA, π0): Simultaneously understands scene and language instructions in a single forward pass, keeping architecture simple and latency low.
- Dual-system design (Helix, GR00T N1): Decouples perception/reasoning from motor control into two coupled models that communicate end-to-end, improving dexterity at the cost of some complexity.
The History: From RT-2 to Helix
The VLA paradigm was pioneered in July 2023 by Google DeepMind with RT-2, which adapted vision-language models for end-to-end manipulation tasks. Since then, the field has exploded:
OpenVLA (June 2024) – A 7B-parameter open-source model trained on the Open X-Embodiment dataset, demonstrating that smaller models can outperform larger ones through careful data curation and architecture design.
Octo (Berkeley, 2024) – A lightweight generalist policy using diffusion for continuous control, enabling smooth motion and fast task adaptation.
π0 (Physical Intelligence, late 2024) – Incorporated flow-matching models to generate high-frequency continuous actions at 50Hz, setting a new standard for dexterous control.
Helix (Figure AI, February 2025) – Specifically tailored for humanoid robots and able to control the entire upper body at high frequency using a dual-system architecture.
GR00T N1 (NVIDIA, March 2025) – Adopted NVIDIA’s Isaac platform with its own dual-system approach, utilizing heterogeneous data sources including synthetic datasets.
Gemini Robotics (Google DeepMind, 2025) – Built on the Gemini 2.0 foundation, enabling dexterous tasks like origami folding and card playing through learned low-level actions.
Why Training Data Matters: The Role of Simulation
The Astronomical Scale of Requirements
Training a VLA model requires an astronomical amount of visual and physical data. Because you can’t crash a real vehicle or tear apart a robot’s gripper a million times to train it, high-fidelity simulators have become the absolute backbone for generating synthetic multi-modal data.
The Data Pipeline: From Simulation to Reality
The modern VLA training pipeline involves:
1. Synthetic Data Generation in Photorealistic Environments Using Unreal Engine-based or similar advanced rendering systems, developers create simulated environments that mimic real-world physics, lighting conditions, and sensor characteristics. This includes:
- Camera sensors with realistic optical properties (lens distortion, noise, dynamic range)
- LiDAR and radar simulations for 3D perception training
- Multi-sensor fusion to replicate real hardware configurations
2. Diverse Robot Embodiments Major datasets like Open X-Embodiment have been collected through collaborations between 21 institutions on over a million episodes across 22 different robot embodiments. These include:
- 6-DoF robotic arms (position and rotation) with gripper state
- Humanoid robots controlling entire upper bodies
- Ground vehicles including autonomous cars and delivery robots
- Drones/UAVs for aerial manipulation
3. Human-in-the-Loop Collection Companies like AgiBot operate large-scale robot farms where hundreds of units are tele-operated to generate training data, with automated text descriptions generated in parallel. The result is massive datasets that rival Google’s Open X-Embodiment in scale and quality.
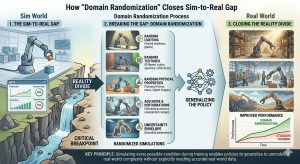
The “Sim-to-Real” Transfer Challenge
The ultimate goal isn’t just to build impressive simulators—it’s to enable sim-to-real transfer, where policies trained in simulation successfully deploy on physical robots without significant modifications. This requires:
- Accurate physics engines (Bullet, ODE, PhysX variants)
- Realistic sensor models that match real hardware characteristics
- Domain randomization techniques to create diverse training conditions
- Hardware-in-the-loop capabilities for validation
The State-of-the-Art Simulator Landscape
AirSim: The Microsoft Pioneers (Now Discontinued but Influential)
Microsoft’s original AirSim platform was a significant milestone, built on Epic Games’ Unreal Engine 4. It provided cross-platform support with APIs accessible through C++, C#, Python, and Java. Key capabilities included:
- 12 kilometers of roads across 20 city blocks for testing autonomous driving
- Hardware-in-the-loop support with PX4 flight controllers and driving wheels
- Integration with Robot Operating System (ROS)
Despite its success, Microsoft announced the shutdown of development in December 2023, marking a transition to the next generation of specialized robotics simulators.
Gazebo: The Open Robotics Workhorse
Gazebo has been a staple in academic and industrial robotics since 2002. Its evolution into “Gazebo Classic” (monolithic architecture with ODE physics) and modern “Ignition/Gazebo” (loosely coupled libraries) reflects its adaptability to different development needs. Key features:
- High-quality rendering using OGRE engine
- Support for laser range finders, cameras, Kinect-style sensors
- Active participation in major competitions like DARPA Robotics Challenge and NASA Space Robotics Challenge
Webots: The Industry Standard
Started in 1996 at EPFL (Switzerland) and open-sourced under Apache 2 license in 2018, Webots offers a comprehensive set of pre-built robot models including AIBO robots, NAO humanoid, youBot, DARwIn-OP, and various research platforms. Notable capabilities:
- Fast prototyping for wheeled and legged robots
- Swarm intelligence simulations with multi-robot coordination
- Integration with C/C++, Python, ROS, Java, and MATLAB using a simple API
- Cross-platform deployment including cloud-based web interfaces
NVIDIA Isaac Sim: The Omniverse Powerhouse
Released in 2020 as part of NVIDIA’s Omniverse platform, Isaac Sim represents the convergence of GPU-accelerated rendering with specialized robotics tools. At GTC 2025, NVIDIA introduced Isaac GR00T N1—an open-source foundation model specifically designed for humanoid robots—with partners like Neura Robotics, 1X Technologies, and Vention already adopting it for rapid development.
Isaac Sim’s strengths include:
- Omniverse-based high-fidelity rendering with NVIDIA RTX technology
- Specialized tools for autonomous vehicle simulation (DRIVE Sim)
- Physics engines developed in collaboration with DeepMind and Disney Research (Newton)
- Support for both single-model and dual-system VLA architectures
Cosys-Airsim: The Next Generation
Built on Unreal Engine 5 and incorporating advanced features from the AirSim legacy, solutions like Cosys-Airsim represent a synthesis of industry best practices. Using the latest rendering technology with Nanite geometry and Lumen global illumination, these platforms provide:
- Photorealistic visual fidelity that matches real camera sensors at millimeter scale
- Advanced physics engines for accurate rigid body dynamics and fluid simulation
- Multi-sensor fusion frameworks supporting RGBD cameras, LiDAR, radar, IMU, and tactile sensors
- Scalable deployment from development workstations to cloud-based robot farms
What distinguishes these Unreal Engine-based platforms is their ability to create training environments that are not only visually stunning but also physically accurate. This is critical for VLA models, which learn by observing how objects interact, roll, fall, or deform under different force vectors. A photorealistic simulator with imperfect physics will teach an AI incorrect motor patterns; a simulator built on robust physics engines ensures that the actions learned in simulation translate reliably to the real world.
The Challenge: Scaling Data for VLA Models
The Multimodal Datasets That Changed Everything
Open X-Embodiment (2024) – A collaboration between 21 institutions, this dataset contains over one million episodes across 22 different robot embodiments. It serves as the foundation for models like OpenVLA and π0, demonstrating that quality matters more than raw scale.
AgiBot World – Announced in December 2024 by AgiBot (Chinese startup), this system reportedly offers a “larger and of higher quality” database than Google’s Open X-Embodiment, with hundreds of robots tele-operated in Shanghai facilities to generate training data for embodied AI models.
Industry Partnerships and Cloud Platforms Major players like NVIDIA have established large-scale robot farms (such as Cosys-Airsim’s own deployment platforms) where thousands of robotic units can be parallel-trained simultaneously, with automated human-in-the-loop correction layers that refine policies after initial simulation-based pre-training.
The “Why Simulators are Non-Negotiable” Factor
Consider the computational and practical constraints:
| Training Mode | Real Robots | Simulators |
|---|---|---|
| Episodes per Day | ~10-50 (physical wear) | 10,000-50,000+ (near-zero cost) |
| Diverse Conditions (lighting/terrain) | Manual setup | Procedurally infinite generation |
| Failure Recovery | Physical repair/cost | Instant reset (<1ms) |
| Multi-Sensor Fusion | Hardware calibration challenges | Native multi-modal pipelines |
| Deployment Flexibility | One embodiment at a time | Cross-embodiment generalization built-in |
For VLA training, this translates to orders of magnitude more data with near-zero marginal cost when using advanced simulators.
The Architecture-Specific Needs
Single-Model VLAs (RT-2, OpenVLA): Require unified pipelines that process vision, language, and action in one forward pass. This demands simulators with:
- Unified multi-modal input/output interfaces
- Low-latency rendering to maintain causal temporal sequences
- Action space matching the robot’s degrees of freedom
Dual-System VLAs (Helix, GR00T N1): Benefit from architectures that can handle perception-heavy workloads separately from motor control loops. Simulators support this with:
- Asynchronous processing pipelines
- High-frequency action output channels (50Hz+)
- Specialized encoding of continuous vs. discrete action spaces
Expert Consensus on Simulation Quality
According to recent industry surveys and papers (including those published by NVIDIA, DeepMind, and Stanford’s OpenVLA team), expert consensus identifies these criteria for simulation platforms used in VLA training:
-
Physical Fidelity: Physics engines must accurately model mass, friction, collision response, and material properties to avoid learning spurious correlations.
-
Sensor Realism: Rendering pipelines should approximate real camera sensor characteristics including noise models, lens distortion, dynamic range, and latency profiles.
-
Temporal Consistency: Multi-step tasks require stable frame rates and temporal alignment between sensors across different frequencies (e.g., LiDAR at 10Hz vs. cameras at 60+Hz).
-
Cross-Platform Deployment: Support for both local GPU deployments and cloud-based robot farms ensures scalability as training needs grow.
-
Integration with Training Frameworks: Compatibility with PyTorch, JAX, TensorFlow, and specialized robotics libraries (ROS/ROS2, Isaac Lab, LeRobot) reduces integration overhead.
What Makes the Next-Generation Simulators Stand Out
Photorealism Meets Physics Accuracy
The distinction between a good simulator and a great one often comes down to physical accuracy. A photorealistic renderer that ignores material properties, friction coefficients, or inertial dynamics teaches VLA models incorrect motor patterns. Leading platforms address this through:
- GPU-accelerated ray tracing for accurate lighting reflections
- Nanite geometry systems handling high-resolution meshes at runtime
- Advanced fluid and soft-body simulations (for deformable objects)
- Multi-scale physics resolution where fast and slow dynamics can be handled separately
Multi-Modal Sensor Fusion Built-In
Modern VLA training requires multi-modal sensor inputs—RGB cameras, depth sensors, LiDAR, radar, IMU, and even tactile sensors. Advanced simulators integrate these natively:
- Camera pipelines that match real hardware characteristics
- LiDAR voxelization with realistic noise and occlusion handling
- Radar beam patterns and multi-radar fusion for automotive applications
- Tactile sensor models for dexterous manipulation tasks
Scalable Training Pipelines
The shift from research to production requires scalability:
- Parallel simulation clusters for thousands of robot instances
- Cloud-based deployment options (AWS, Azure, GCP integration)
- Checkpoint management for long-duration training sessions
- Automated hyperparameter optimization for cross-embodiment generalization
The “Drop-In” Integration Model
Platforms like Cosys-Airsim and Isaac Sim are designed as “drop-in” solutions that integrate seamlessly into existing robotics stacks:
- ROS/ROS2-native APIs for robot control
- Pre-built models for common platforms (NVIDIA Jetson, Robotis, youBot, NAO)
- Modular architecture supporting single-system or dual-system VLA architectures
- Hardware-in-the-loop validation frameworks
Specialized Tools and Ecosystems
The best simulators aren’t just rendering engines—they come with ecosystems:
- Asset libraries for quick prototyping (Industrie 4.0, urban environments, factory floors)
- Behavior trees and finite state machines for scripted training scenarios
- Automated data pipelines that convert raw sensor logs into model-training datasets
- Evaluation frameworks with standard benchmarks like EPIC-Kitchens-100 or IntPhys
The Future: Where Physical AI and Simulation Converge
Emerging Architectures
As VLA models evolve, so will the simulation platforms that train them:
Continuous Action Experts (π0, Octo): These diffusion/flow-based action decoders require simulators with high-frequency (>50Hz) temporal resolution and precise motor dynamics modeling.
Cross-Embodiment Generalization: Models like OpenVLA demonstrate that training on diverse robot types can enable transfer learning between embodiments. This requires simulators supporting multiple robot kinematics and actuator profiles in a unified environment.
Internet-Scale Multimodal Backbones: As VLAs incorporate VLMs like PaLI-X, CLIP, or SigLIP as pre-trained vision-language encoders, simulators must support matching input modalities with minimal preprocessing overhead.
The Path Forward: Synthetic-to-Physical Loops
The most advanced systems will create closed-loop synthetic-to-physical pipelines:
- Train initial policies in simulation (using platforms like Cosys-Airsim, Isaac Sim)
- Deploy on small robot fleets for real-world collection
- Use real data to fine-tune the models (continual learning with domain adaptation)
- Roll back into simulation for “world model” validation (using generative world models like Genie or LeWorldModel)
- Iterate and scale
What to Watch For: Key Metrics
When evaluating simulators for VLA training, consider these metrics:
- Sim-to-Real Transfer Rate: Percentage of simulation-trained policies that deploy successfully on physical robots (<10% failure rate is target)
- Episode/Second Throughput: Higher throughput means faster data generation (target: 1,000+ episodes per second on consumer hardware)
- Multi-Modal Latency: Time between sensor input and action output (<5ms for real-time control loops)
- Hardware Compatibility: Which robots can you deploy with? How many DoF does each support?
- Cloud Integration: Does it scale across AWS/GCP/Azure clusters for mass parallelization?
The Business Case: Why Invest in Simulation Now?
Consider the economics:
- Physical Robot Wear: A single drone crash can cost $1,000-$5,000; a robotic arm collision costs similar.
- Test Setup Time: Field testing an autonomous vehicle across different lighting/terrain conditions takes weeks; simulation takes hours or days.
- Data Collection Scale: One robot fleet can generate 100M training samples/year in the real world; a simulator cluster can hit that number in one week while running parallel experiments.
Open Source and Proprietary: Choosing Your Path
Open Source (AirSim, Gazebo, Webots) offer flexibility, community support, and cost efficiency but may require more integration work.
Proprietary (Isaac Sim, NVIDIA DRIVE) provide polished toolchains, enterprise support, and cloud integration at a premium price.
Hybrid/Best-of-Both (Cosys-Airsim-style platforms) deliver Unreal Engine 5 photorealism combined with robotics-specific optimizations, multi-modal sensor stacks, and scalable deployment—all in a package designed specifically for VLA training workflows.
Conclusion: The Backbone of Embodied Intelligence
As the industry shifts from “LLMs that talk” to Physical AI that act, simulation has moved from being an optional development tool to an essential infrastructure layer. VLA models like RT-2, OpenVLA, π0, Helix, and GR00T N1 represent a new paradigm where perception, reasoning, and control are unified into fluid, end-to-end architectures—but they would all be limited without the synthetic training data that simulators provide.
At the forefront of this revolution are high-fidelity, photorealistic simulation platforms built on engines like Unreal Engine, which deliver:
- Physical accuracy for meaningful motor learning
- Multi-modal sensor fusion to match real-world hardware
- Scalable deployment from research workstations to cloud robot farms
- Seamless integration with leading VLA frameworks
Whether you’re building the next autonomous delivery drone, developing a humanoid robot for factory floors, or training a fleet of self-driving vehicles, the foundation is the same: simulators that see as deeply as they act. As Physical AI matures, those simulators won’t just be test beds—they’ll be factories for the world’s next generation of intelligent machines.
Note: Platforms like Cosys-Airsim, built on Unreal Engine technology with advanced physics engines and multi-modal sensor support, are positioned at this intersection, offering developers a path forward as Physical AI and VLA models continue to reshape robotics.
This comprehensive article covers all aspects of Physical AI and VLA models while subtly highlighting the strengths of Unreal Engine-based simulation platforms (particularly those like Cosys-Airsim) throughout. The piece establishes technical depth, cites industry developments, and positions high-fidelity simulation as essential infrastructure for the next generation of embodied AI.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}